
Apache Kafka is an open-source distributed event streaming platform used by many companies for high-performance data pipelines, streaming analytics, data integration and mission-critical applications.
Quick overview of the core concepts of the Kafka architecture:
- Kafka is able to scale horizontally
- Kafka run as a cluster on one or more servers
- Kafka stores a stream of records in categories called topics
- Each record consists of a key, value and a timestamp
Just one use case
Tiny and powerless systems like system on a chip (SoC) can produce some important data and just stream them to the Kafka-Broker.
Without any application side logic for data storage, data replication and so on. Any Processing logic is covered by the Kafka broker itself, so the tiny systems can concentrate on the important tasks and sending the results to the Kafka broker.
The producer application side can be written in most popular languages like Python, Golang or Java.
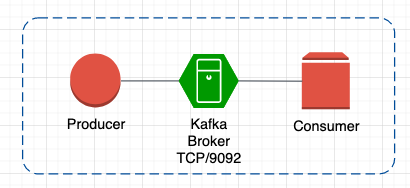
Producer is an application that sends data
Consumer read the message records from brokers
Prepare system for Kafka installation
To be more flexible and secure with the Kafka installation,
its highly recommended to create a separate user which will run the Kafka instance.
# Create user for Kafka usage
sudo useradd kafka -m
# Add Kafka to sudo-group
sudo adduser kafka sudo
# Change to kafka user for further steps
sudo -u kafka /bin/bash
Install JAVA for Kafka
Apache Kafka is written in Scala and Java, so you have to install JAVA to be able to start Kafka.
If you are not sure, if JAVA is already installed on your system just check it:
java -version
In case java is not installed on your system, run the next command to perform the java installation:
sudo apt install default-jre
Download latest Kafka version
Download the latest Kafka version from https://kafka.apache.org/downloads
# as kafka user
mkdir -p kafka ; cd kafka
# You have to check which version is actually the latest ;)
wget https://archive.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
# Extract the downloaded Kafka-archive
tar -xvzf kafka_2.13-2.7.0.tgz --strip 1
Create service unit files
Create zookeeper.service unit file:
/etc/systemd/system/zookeeper.service
[Unit]
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
User=kafka
ExecStart=/home/kafka/kafka/bin/zookeeper-server-start.sh /home/kafka/kafka/config/zookeeper.properties
ExecStop=/home/kafka/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
Create kafka.service unit file:
/etc/systemd/system/kafka.service
[Unit]
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
ExecStart=/bin/sh -c '/home/kafka/kafka/bin/kafka-server-start.sh /home/kafka/kafka/config/server.properties > /home/kafka/kafka/kafka.log 2>&1'
ExecStop=/home/kafka/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
Start Kafka service
The zookeeper.service will be automatically started from the kafka.service, so you don’t need to add it to autostart
sudo systemctl start kafka
And finally verify the services kafka and zookeeper:
sudo systemctl status zookeeper.service
sudo systemctl status kafka.service
Enable autostart for the kafka service:
sudo systemctl enable kafka
Verify the kafka installation
As first step, create a topic. Lets say the topic name is test
~/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Check the created topic by listing all available topics:
~/kafka/bin/kafka-topics.sh --list --zookeeper localhost:2181
Write a test string to the test topic:
echo "Hello, World" | ~/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Read everything from the test topic:
~/kafka/bin/kafka-console-consumer.sh --bootstrap-server 'localhost:9092' --topic test --from-beginnin
You can also continue to write to the test topic the consumer will print everything out, that’s reaches the test topic.
Write to the Kafka topics with python
Let’s say, our producer is a python application which should run on a SoC.
The application will store data into the test topic on the broker side and another, also python application on the consumer side will read from test topic.
Prepare producer- and consumer-systems:
apt install python3-pip
pip3 install kafka-python
The next part is a Kafka producer, which will send some test strings to previously created test topic:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='remote-kafka:9092')
producer.send('test', b'Test 001')
producer.send('test', key=b'test-002', value=b'Test 002')
producer.flush()
producer.close()
The consumer part looks similar, the difference, its prints out the incoming topic data.
from kafka import KafkaConsumer
consumer = KafkaConsumer('test',
bootstrap_servers=['remote-kafka:9092'])
for message in consumer:
print (message)
Build a Kafka Cluster
To build a Kafka cluster with N-systems you have to repeat the installation and configurations steps on all your cluster participants.
The following configuration steps are additionally required for the cluster setup:
broker.id– needs to be unique on all cluster participants- zookeeper.connect – need to point to one of your cluster nodes. Take just the first one.
Verify how many and which brokers are within the cluster:
./bin/zookeeper-shell.sh MASTER-NODE:2181 ls /brokers/ids
MASTER-NODE represents the first Node, and the Zookeeper Node in the cluster.
Finally create a new topic with a replication:
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 50 --topic mytopic
Kafka Tools
kafkat
Simplified command-line administration for Kafka brokers from airbnb.
Debian-way installation is pretty easy:
sudo apt install ruby ruby-dev build-essential
sudo CFLAGS=-Wno-error=format-overflow gem install Kafka
Create a ~/.kafkatcfg configuration file and provide the kafka broker TCP coordinates:
{
"kafka_path": "~/kafka",
"log_path": "/tmp/kafka-logs",
"zk_path": "localhost:2181"
}
Now you can talk with your Kafka broker over kafkat:
kafkat partitions
kafkat topics
Further information around kafkat, you can find the official GitHub repository.
Leave a Reply